Google’s PageRank and Beyond: The Science of Search Engine Rankings
Chapter 1: Introduction to Web Search Engines
- Information retrieval is the process of searching within a document collection for a particular information need (called a query)
- In the past, people learned valuable websites from other people’s recommendation. All this changed in 1998 when link analysis hit the information retrieval scene. The most successful search engines began using link analyasis, a technique that exploited the additional information inherent in the hyperlink structure of the web to improve the quality of search results.
- PageRank link analysis algorithm used by Google
- HITs algorithm used by Teoma
- Traditional nonlinked information retrieval
- boolean model: operates by considering which keywords are present or absent in a document
- pros:
- simple to implement
- query can be processed quickly and in parallel
- scale well
- cons:
- no concept of a partial match (hard to deal with synonymy and polysemy)
- sometimes require user to have knowledge about engine’s specialized syntax in order to have better result
- pros:
- Vector space model: transform textual data into numeric vectors and matrices, then employ matrix analysis techniques to discover key features and connections in the document collection (e.g. LSI engine).
- pros:
- it has relevance scoring: the vector space odel allows documents to partially match a query by assigning each document a number between 0 and 1 which can be interpreted as the likelihood of relevance to the query.
- it has relevance feedback: information retrieval tuning technique. It allows the user to select a subset of the retrieved documents that are useful and then resubmit with this additional relevance feedback information.
- cons:
- hard to scale because need to compute distance between each document and the query.
- pros:
- probabilistic model: estimate the probability that the user will find a particular document relevant. It can operate recursively and update the priori preferences.
- pros:
- it can tailor search results to preferences of individual users
- cons:
- hard to build, hard to scale
- unrealistic simplifying assumptions. For instance, it assumes independence between terms as well as documents
- pros:
- Meta-search engine: a combination of several search engines and some subject-specific search engines.
- boolean model: operates by considering which keywords are present or absent in a document
- Evaluate search engines (traditional)
- precision: the ratio of the number of relevant documents retrieved to the total number of documents retrieved.
- recall: the ratio of the number of relevant documents retrieved to the total number of relevant documents in the collection. Good engine has both good precision and recall.
- time (latency, response time)
- space usage
- Web information retrieval
- Challenges
- huge: billion of pages, PB level of data
- dynamic: quite different from traditional document collections which is almost staic, web changes all the time. The larger the web in size, the more often and extensively it will change. The dynamic of the web make it tough to compute relevancy scores for queries when the collection is moving.
- self-organized: no standards and no gatekeepers policing content, structure and format. Spammers can mislead metatag descriptions to fool early web search engines (entertaining game of cat and mouse between search engines and spammers).
- hyperlinked: it makes the new national pastime of surfing possible and make focused, effective search a reality.
- Users’ ability to look at documents do not grow (users rarely look beyond the first 10 to 20 documents retrieved). So search engine precision must increase just as rapidly as the number of documents is increasing.
- the evaluation of web search engine is more based on user satisfaction, market share, speed, storage
- Elements of web search:
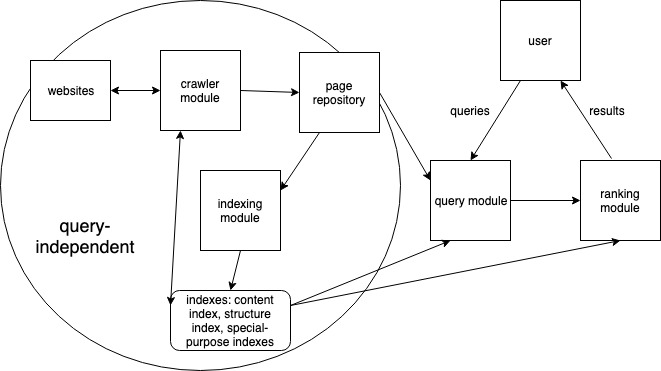
- query independent:
- crawler module: collect and categorize web’s documents. It creates virtual robots (spiders) that constantly scour the web gathering information and webpages and returning to store them in a central repository.
- page repository: temporarily store full, complete webpages (until sent to indexing module). And permanently store pupular pages.
- indexing module: takes each new uncompressed page and extracts only the vital descriptors, creating a compressed description of the page that is stored in various indexes.
- indexes:
- content index: content such as keyword, title, anchor text for each webpage is tored in a compressed form using inverted file strucutre.
- structure index: store hyperlink structure of pages. The crawler module can access the structure index to find uncrawled pages.
- special purpose indexes: For instance, indexes such as the image index, pdf index hold information that is useful for particular query tasks.
- query dependent: search engine must respond in real-time
- query module: convert natural language to a language that the search system can understand and consult various indexes in order to answer the query
- ranking module: takes relevant pages and ranks them according to some criterion. The outcome is an ordered list of webpages such that the pages near the top of the list are most likely to be what the user desires. The ranking combines content score (e.g. many web engines give pages using the query work in the tile or description a higher content score than pages using the query word in the body of the page) and popularity score (determined from an analysis of the web’s hyperlink structure).
- query independent:
- Challenges
Chapter 2: Crawling, indexing and query processing
- crawling module: instruct robots or spiders on how and which pages to retrieve. It returns with URLs for new or refreshed pages that need to be added to or updated in the search engine’s indexes.
- which page to crawl?
- How ofter should pages be crawled? A crawler must decide which pages to revisit and how often. Some engines make this decision demorcratically while others refresh pages in proportion to their preceived freshness or importance levels.
- How should pages be crawled ethically? When a spider crawl a page, it consumes bandwidth and hits quotas belonging to the page’s host. Robots Exclusion Protocol was developed to define proper spidering activities.
- content index: store the textual information for each page in compressed form
- valuable information is contained in title, description and anchor text as well as in bolded terms, terms in large font and hyperlinks
- inverted file can be built (e.g. term 1 - file 1,2,3; term 2 - file 2,3,4). But it also involves difficulty.
- the number of webpages using pupular broad terms is large
- webpage id is usually not the only descriptor for a term (other descriptor such as location of the term, apperance of the term are also important)
- if a page change its content, so must their compressed representation in the inverted file
- enormous inverted file must be stored on a distributed architecture. So strategies for optimal partitioning must be designed.
- query processing:
- Google likes to keep their processing time under half a second, so the query module have to accesses precomputed indexes such as the content index and the structure index.
- the ranking module accesses precomputed indexes to create a ranking at query-time.
- the content score can be computed solely from the content index and its inverted file and is query-dependent. The popularity score is computed solely from the structure index and is usually query-independent. The overall score can be computed by the multiplication of those two scores.
Chapter 3: Ranking webpages by popularity
- The popularity score became a crucial complement to the content score and provided search engines with impressively accurate results for all types of queries.
- HITS (hypertext induced topic search) by Jon Kleinberg: A page is considered a hub if it contains many outlinks. A page is called an authority if it has many inlinks. A page can be both a hub and an authority. A page is good hub if it points to good authorities, and a page is a good authority if it is pointed to by good hubs.
- PageRank by Sergey Brin and Larry Page: A page with more recommendations is likely to be more important than a page with a few inlinks. The status of the recommender is also important. The weight of each endorsement should be tempered by the total number of recommendations made by the recommender.
- A ranking is called query-independent if the popularity score for each page is determined off-line and remains constant until the next update regardless of the query.
Chapter 4: The mathematics of Google’s Pagerank
- TODO